何謂結帳,該如何製作結帳分錄?
(1) 企業以製作分錄寫日記的方式,記載了企業的經濟事項,稱為日記簿。
再依日記簿各項目予以分類,以了解各項目之明細,稱為分類帳。
分類帳是各項目明細,但非為該項目之餘額,所以依各項目之餘額,進行試算,編製試算表。
試算表中包含有所有有餘額之會計項目及其餘額。
(2) 各項目餘額舉例如下:
現金借餘 987,500
應收股東往來借餘 20,000
存貨借餘 16,000
預付費用借餘 30,000
運輸設備借餘 80,000
累計折舊-運輸設備貸餘4,000
預收貨款貸餘 100,000
股本貸餘 1,000,000
營業收入貸餘 160,000
營業成本借餘 64,000
薪資支出借餘 30,000
租金支出借餘 30,000
文具用品借餘 1,500
水電瓦斯費借餘 1,000
折舊費用借餘 4,000
依上述各項目之借方餘額應等於貸方餘額,則試算表為平衡。
(3) 以上項目再分類為資產、負債、權益、收益、費損共5類。資產、負債、權益(以上三類稱實帳戶)金額會轉成下一年度期初餘額,但收益、費損(以上二類稱虛帳戶)會被結清,舉例:12月31日帳上銀行存款1億,於下一年度1月1日銀行存款金額,還會在。但收益、費損結清後會編製成損益表,例如:今天營收2億,成本1億8千萬,則於年度結清為本期損益2000萬,下一年度1月1日營收從零開始。
(4) 延上例,以下項目屬虛帳戶
營業收入貸餘 160,000
營業成本借餘 64,000
薪資支出借餘 30,000
租金支出借餘 30,000
文具用品借餘 1,500
水電瓦斯費借餘 1,000
折舊費用借餘 4,000
(5) 虛帳戶之結清,應另設立「本期損益」帳戶,將其他各項損益之餘額彙總至「本期損益」帳戶中。
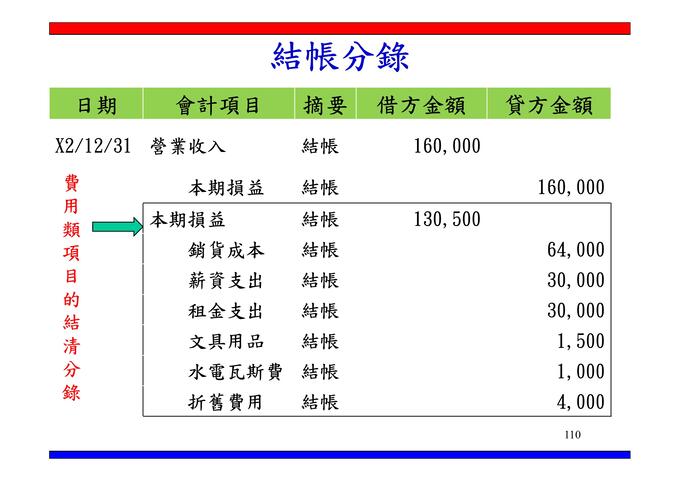
A營業收入貸餘 160,000
將營業收入貸餘轉借方後對方項目為「本期損益」
借:營業收入 160,000
貸:本期損益 160,000
B各項成本費用借餘轉貸方後對方項目為「本期損益」
借:本期損益 130,500
貸:營業成本 64,000
薪資支出 30,000
租金支出 30,000
文具用品 1,500
水電瓦斯費 1,000
折舊費用 4,000
C於試算表中,則本期損益則為貸餘29,500
(6)結帳後之試算表如下:
現金借餘 987,500
應收股東往來借餘 20,000
存貨借餘 16,000
預付費用借餘 30,000
運輸設備借餘 80,000
累計折舊-運輸設備貸餘4,000
預收貨款貸餘 100,000
股本貸餘 1,000,000
本期損益貸餘 29,500
則該試算表借方總額等於貸方總額,該試算表「平衡」。
百大會計師事務所 蔡淑惠會計師